|
I am a master student working on open-world representation learning and image super-resolution at Shanghai Jiao Tong University. I received my bachelor degree from Shanghai Jiao Tong University (SJTU) in June 2021. My current research interest is in open-world representation learning. |

|

|
Ziyi Li* , Qinye Zhou* , Xiaoyun Zhang , Ya Zhang , Yanfeng Wang , Weidi Xie International Conference on Computer Vision (ICCV), 2023 we propose to augment a pre-trained text-to-image diffusion model with the ability of open-vocabulary objects grounding, i.e., simultaneously generating images and segmentation masks for the corresponding visual entities described in the text prompt. |
|
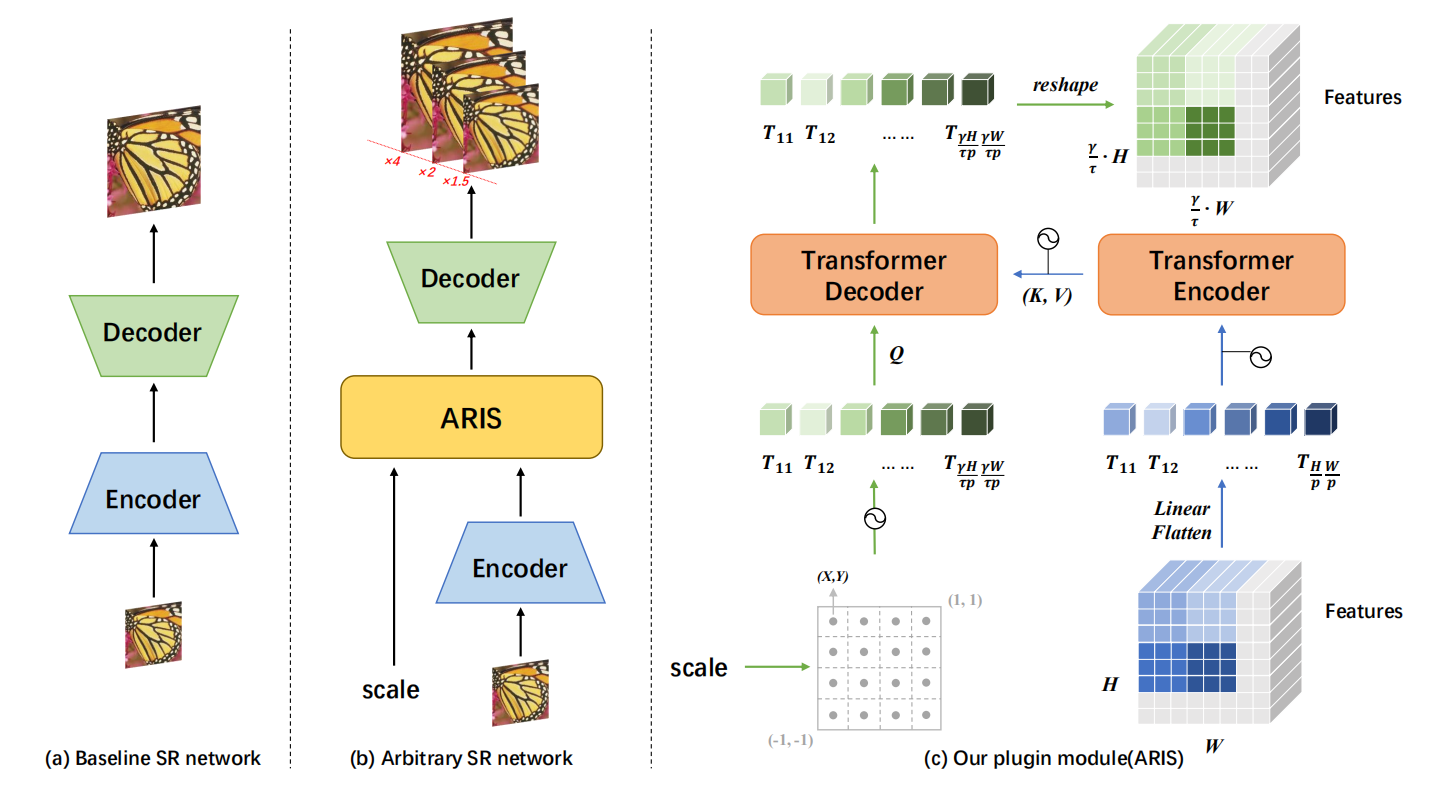
Qinye Zhou* , Ziyi Li* , Weidi Xie , Xiaoyun Zhang , Yanfeng Wang , Ya Zhang British Machine Vision Conference (BMVC), 2022 we propose to develop a general plugin that can be inserted into existing super-resolution models, conveniently augmenting their ability towards Arbitrary Resolution Image Scaling, thus termed ARIS. |
|
Based on a template by Jon Barron.
|